
Workshop
- Automatic Web scraping (2021-08-01)
- Exporting history 3 (2020-06-30)
- Italic and non-italic Greek symbols in LibreOffice formula editor (2020-02-12)
- Bluetooth and "default" directories in Ubuntu Linux (2012-11-17)
- Exporting Firefox history 2 (2012-10-20)
- Windows 98 theme for GNOME/Metacity (2011-01-29)
- Ejecter (2010-03-07)
- Exporting Firefox history (2010-01-11)
- Fighting ISP redirects (2009-08-17)
- MAF 0.12.3 out (2009-05-18)
- GTK 1.2 font issues (2009-05-16)
- chmod recursively (2009-02-01)
- FlightGear init script (2008-07-19)
- *.mht file issues (2008-07-06)
- Interactive directory opened (2008-04-05)
- Abandoning ICQ chat protocol (2008-03-20)
- Getting rid of .serverauth.???? files (2008-03-19)
- Cleaning up Ubuntu installation (2008-03-07)
- How to play Shockwave on Linux (2008-02-19)
- Older
- Miscellaneous
Automatic Web scraping
2021-08-01I have done Web scraping a few times in the last two years, either to download a large number of elements that would be time-consuming to download by hand, or to extract some periodically updated information from a website. Before, I used R XML package to parse HTML pages. In the last year, I was receiving daily inspirational quotes as images from some organization by WhatsApp, and after a considerable number of them accumulated in the downloads folder, it occurred to me that they could probably processed in an efficient way and analyzed afterwards as an exercise.
The name of this organization, as shown on those images, is Brahma Kumaris, and, after a simple Web search, I found several social-network accounts of it, on some of which they posted those images with daily quotes. For the analysis of already downloaded images, the WhatsApp folder suffices, but WhatsApp is such a closed and limited media that to be able to catch and process the new images, scraping the pages of those social-network profiles would be much more feasible. I chose their Twitter account, bk_colombia, for the scraping purpose, where they post those images and other content. Not so easy: if you look at the page source, it's all JavaScript, with no user content directly in the code.
So I needed a Twitter scraping tool. There are quite a few, but there is a catch: you need a Twitter account to enable its API. I have never had one and am not planning to obtain one, so I searched on, until I found twint, which doesn't require any authentication and processes a Twitter account's content into a CSV table from the given date until now. (Note: it didn't work right away for me; the solution is here, without reinstalling.) That's what was needed, and, after generating a CSV table with the links to the images there, it could be processed further. For example, to download the content for yesterday and today:
#!/bin/bash YESTERDAY=$(date -d '1 day ago' '+%Y-%m-%d') TODAY=$(date '+%Y-%m-%d') twint -u bk_colombia --since $YESTERDAY --images -o kumaris-daily.csv --csv
Looking at the structure of the CSV table, we can extract the links to the images, for example, with the following R script; also, you can see that the posting of the image for the given day sometimes happens in the previous day (within 2 hours of midnight), so to extract the correct date, we can put the time forward by, say, 4 hours using lubridate.
maindir = "[DIRECTORY TO THIS SCRIPT]"
library(lubridate)
tweets = read.csv(paste0(maindir, "/kumaris-daily.csv"), sep = "\t")
tweets$created_at = as.character(tweets$created_at)
tweets$photos = as.character(tweets$photos)
tweets$created_at_fwd = NA
for (i in 1:length(tweets$created_at)) {
tweets$created_at_fwd[i] = as.POSIXct(tweets$created_at[i]) + hours(4)
}
tweets$created_at_fwd = as.POSIXct(tweets$created_at_fwd, origin = "1970-01-01")
tweets.today = tweets[as.Date(tweets$created_at_fwd) == Sys.Date(),]
for (i in 1:length(tweets.today$photos)) {
url = gsub("\\'", "", gsub("\\]", "", gsub("\\[", "", tweets.today$photos[i])))
day = as.POSIXct(tweets.today$created_at_fwd[i])
filepath = paste0(maindir, "/kumaris_", as.Date(day), ".jpg")
if (file.exists(filepath)) {
filepath = paste0(gsub(".jpg", "", filepath), "_.jpg")
}
download.file(url, filepath)
}
Now we have downloaded the images, but besides the image with the daily quote, sometimes there are other images they post. Notice that the image with the quote always has the title "Regalo para el alma", so we can OCR and detect it, deleting other images, if any. I use tesseract for OCR. It's enough to detect "regalo para" (caps or lowercase).
#!/bin/bash
for f in kumaris_*.jpg; do
tesseract $f $f.txt -l spa --dpi 300
if ! grep -q '[rR][eE][gG][aA][lL][oO] [pP][aA][rR][aA]' $f.txt.txt; then
rm $f $f.txt.txt
fi
done
rm kumaris_*.jpg.txt.txt
For the images that passed this test, we know they most probably contain the quote. To reduce the amount of "trash" (unneeded extra symbols) generated during OCR, we notice that the image has a well-defined layout, with the quote on the left side and a picture on the right side. We can cut out the part with the quote: get rid of 41% of the right side, 14% of the top and 1% of the bottom (found by trial and error) using ImageMagick's "convert" utility, and then OCR the cut-out part.
#!/bin/bash
for f in *.jpg; do
convert $f -gravity East -chop 41%x0 - | convert - -gravity South -chop 0x1% - | convert - -gravity North -chop 0x14% cut_$f
done
tesseract cut_kumaris_$TODAY*.jpg kumaris_$TODAY -l spa --dpi 300
Then we clean up the text files by looking at how well they got generated; we delete anything that's not the quote, including newlines.
#!/bin/bash
for f in kumaris_$TODAY.txt; do
sed -i '/[kK][uUoO][mM][aA][rR][iItToO][sS]/d' $f # delete lines containing "Kumaris", "Komaris", "Kumarts" etc
sed -i '/[rR][eE][gG][aA][lL][oO] [pP][aA][rR][aA] [eE][lL] [aA][lL][mM][aA]/d' $f # delete "Regalo para el alma" line
sed -i '/^$/d' $f # delete empty lines
sed -i '/^..$/d' $f # delete lines with only two symbols
sed -i '/^.$/d' $f # delete lines with only one symbol
sed -i '/Enero/d' $f # Delete date lines
sed -i '/Febrero/d' $f
sed -i '/Marzo/d' $f
sed -i '/Abril/d' $f
sed -i '/Mayo/d' $f
sed -i '/Junio/d' $f
sed -i '/Julio/d' $f
sed -i '/Agosto/d' $f
sed -i '/Septiembre/d' $f
sed -i '/Octubre/d' $f
sed -i '/Noviembre/d' $f
sed -i '/Diciembre/d' $f
sed -i '/Compártelo a quien/d' $f
done
tr '\n' ' ' < kumaris_$TODAY.txt > kumaris2_$TODAY.txt
rm kumaris_$TODAY.txt
mv kumaris2_$TODAY.txt kumaris_$TODAY.txt
That's it, the quote is in the file with the corresponding date in the name. Now it can be converted into HTML and with a little bit of bash joined into a daily-updated HTML file using cron, which then can be uploaded. Here is the result. Due to this server's limitations, the encoding is wrong; choose "Unicode" or "UTF-8" in your browser to see Spanish accented characters correctly.
If you analyze the content, even just by looking at it, you can notice that they made the quotes for each day of the year, and in the next year they repeat. Thus, they have 366 quotes all in all.
2021-09-29 UPDATE: The collected daily quotes were enough to process them and make a table for each corresponding day. Here is the table for every day of the year, based on their quotes beginning 2019-11-11.
2022-05-13 UPDATE: In 2022 they started posting new quotes, different from the repeated quotes from before. Here is the table for 2022 so far.
Exporting history 3
2020-06-30(Update to the previous entries 2012-10-20, 2010-01-11.) I wrote a script in R that exports browser history (Mozilla-like, such as Seamonkey and Firefox, and Chrome-like, such as Chrome, Vivaldi and modern Opera) into an RDS or CSV file, with various options. The help is invoked as "Rscript gethist.r -h". It is raw and not profoundly tested, but in my case it does its job.
For example, to extract Firefox history into an RDS file ffhist.rds: "Rscript gethist.r FF -x mycomputer ffhist.rds" (the script reads all existing profiles in the default location). The columns of the history table are "date" (UTC), "url", "title" and "device". In this example, the device name is given as "mycomputer".
To add extracted history file to an existing RDS file (for example, a large history database) database.rds: "Rscript gethist.r NA -a ffhist.rds database.rds".
The above two tasks can be done as one, by directly adding existing Firefox history to the database: "Rscript gethist.r FF -xa mycomputer database.rds". gethist.r checks for duplicates, so adding to the database is idempotent (adding the same history again with the same device name will report 0 entries added).
To convert the database from RDS to CSV: "Rscript gethist.r NA -c ffhist.rds ffhist.csv"
To dump all available Web history on a Linux device into a CSV file, a bash script like this one can be used:
#!/bin/bash
browsers=("SM" "FF" "GC" "CH" "VV" "OP")
for BR in ${browsers[*]}; do
Rscript gethist.r $BR -x mydevice "$BR"_hist.rds
done
histf=(`ls -d *_hist.rds`)
f0=${histf[0]}
echo $f0
for f in ${histf[*]}; do
if [ "$f" != "$f0" ]
then
Rscript gethist.r NA -a $f $f0
rm $f
fi
done
mv $f0 ALL_hist.rds
Rscript gethist.r NA -c ALL_hist.rds ALL_hist.csv
On Windows, a similar batch script can be made.
Italic and non-italic Greek symbols in LibreOffice formula editor
2020-02-12I am used to having italicized Latin variables and non-italicized Greek variables in printed text - probably because in older Russian books this was standard formatting. Nowadays textbooks tend to italicize everything. My preferred behavior was the default in an older version of OpenOffice/LibreOffice, but newer versions changed this into italicizing Greek variables. A Web search brought me here (where, by the way, the person wanted the opposite behavior), and the solution was to edit the file ~/.config/libreoffice/4/user/registrymodifications.xcu where the parameter GreekCharStyle can take the value of 0 (non-italic Greek variables), 1 (italic Greek variables) and 2 (italic lowercase and non-italic uppercase Greek variables). In my LibreOffice 6, however, the above-mentioned file does not contain this parameter. After some local search, the parameter turned up to reside in /usr/lib/libreoffice/share/registry/main.xcd. After setting it to 0, my preference was enabled. (By the way, this time the default value was "2"!)
Also, it is possible to edit this from GUI via the page mentioned before: Tools -> Options -> Advanced -> Expert Configuration -> Search for "GreekCharStyle" parameter and set the preferred one.
Bluetooth and "default" directories in Ubuntu Linux
2012-11-17I had a problem with the so-called "default" directories apparently defined by freedesktop.org created with every new boot-up when bluetooth was on, particularly "Downloads" and "Public". Apart from this idea's being quite questionable at least (a user should decide himself how to name his own directories!), I could not figure out how to get rid of their being created every time, besides the palliative solutions like running a boot script deleting them or turning off bluetooth in BIOS (which I have been doing since I rarely use bluetooth). The solution was found by chance here and later here: the config file is in ~/.config/user-dirs.dirs; the global settings, just in case (for me, tweaking the local ones worked), are in /etc/xdg/user-dirs.defaults .
Exporting Firefox history 2
2012-10-20(Update to the previous entry.) Finally, there is an extension that does this: History Export. It does not work for older versions of Firefox (refused to work on FF 4.0.1), but it works well on Firefox 16. It exports fewer details than the f3e tool described earlier, but it does export the most essential data: date, URL, page title.
By the way, the f3e site firefoxforensics.com ceased to exist. I saved the tool here.
Windows 98 theme for GNOME/Metacity
2011-01-29For personal reasons, I like the look of Windows 98 GUI. Here is how I managed to theme Ubuntu Linux 10.04.
- Download and install the gtkrc file as directed below (that is, put it in /usr/share/themes/Redmond/gtk*). Choose "Redmond" in your current GNOME theme settings on the "Controls" tab.
- Install this
Win98 icon theme(2011-07-03 update: here is the new version 0.2 with more icons; 2013-07-14 update: version 0.3). I made it using this theme by adding more icons. Apply it. - Install this Win98 Metacity theme. I made it using this theme by changing the colors of the title bar. Apply it.
- Start gconf-editor and go to /desktop/gnome/interface/toolbar_style. Set the value to "both".
- Set your desktop background color to RGB 0 128 128.
- Restart X and enjoy. Screenshot.
- 2011-07-03 UPDATE: Now I put the Win98 start button inside this theme. If you want to add it, go to the Configuration Editor (gconf-editor), go to /apps/panel/objects/object_0. There, enable use_custom_icon and change the value of custom_icon to /home/[your_username]/.icons/win98/scalable/start.png.
- 2014-10-23 UPDATE: This also works for MATE desktop envirnoment, which is forked from GNOME 2.
{kind=link}
Ejecter
2010-03-07A very nice utility that lets you unmount removable media from the system tray in Gnome.
Exporting Firefox history
2010-01-11I like to keep my Web history, so I archive it into a spreadsheet once a year. When I was faced with the problem of exporting history from FF3's places.sqlite, I found, using SQLite Manager, that it keeps the history in two tables, synchronizing which would be a lot of work. I found a great Windows command-line tool f3e which exports FF3's Web and download history with several options available. ("wineconsole f3e.exe" in Linux command line.) The one that makes a "CSV Web report" worked for me as I could easily import the CSV file into the spreadsheet.
When I decided to add some older Web history to the spreadsheet from FF2 history database (which, unlike FF3's places.sqlite, is stored in history.dat), I found MozillaHistoryView, which is meant for FF2 and earlier. However, it was not very useful for me because it could not export Cyrillic letters correctly. The simple answer was found here: close FF3, delete places.sqlite, copy/overwrite history.dat with the one to export from, start FF3. It will rebuild its places.sqlite from history.dat and then you can use f3e as described above.
Fighting ISP redirects
2009-08-17It hasn't been long since I noticed some strange behavior in my browser which looked too much like malware attack, but since using NoScript on Firefox on Linux reduces such risks to a negligible minimum, I attributed the problem to some profile glitches, possibly in the recently installed extensions, and ignored it. The above-mentioned behavior occurred when I requested a nonexistent URL: instead of the browser's 404 page, it was redirected to a page with a Yahoo search (who still uses it nowadays, anyway?) with the search string being the mistyped URL. The page belonged to my provider, Charter, and after testing (and finding) this problem in other browsers, I got it.
After some search, I found more info about it.
The situation being rather unpleasant, I began looking for the solution. One seemed easy: at the bottom of the page they put "More about this page", where, in turn, was the option "Opt out", which, again, on the third click, gave me the page with choices: "Opt in (recommended)" (!) and "Opt out" with the choices of Google, other search engines, and "None". Hoping I got rid of the annoyance, I chose "None" and tested again... The result was unbelievable.
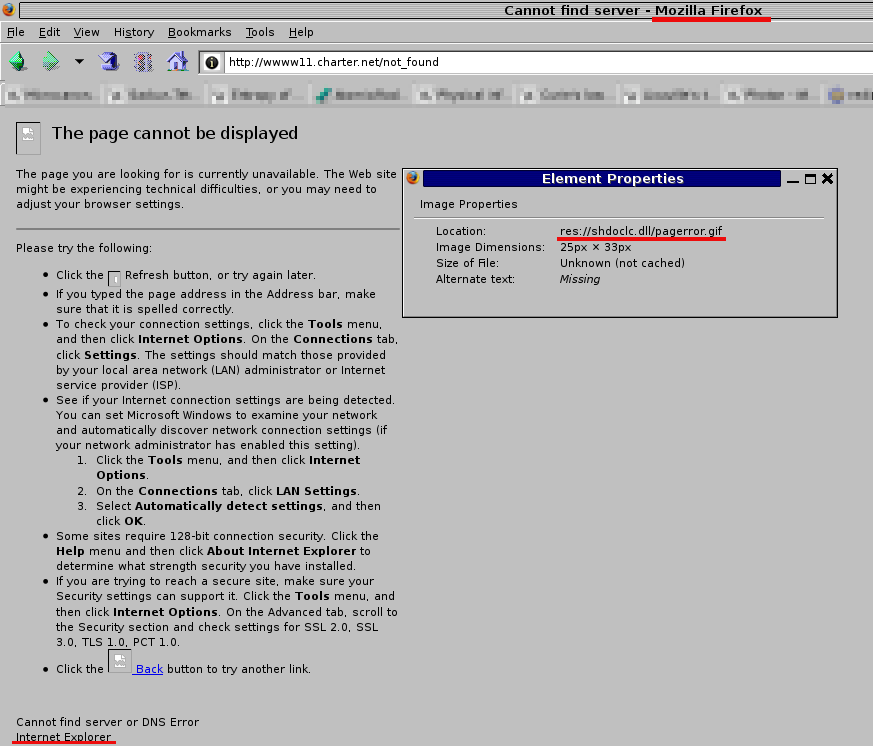
As it can be seen, the redirect did not go away, but they apparently thought I would think it did and therefore put the Internet Explorer error page copy with the images referring to shdoclc.dll in Windows. Therefore, they also thought I used Windows and that I used Internet Explorer.
Still surprised that anyone in a serious business could make something of this kind, I looked for more feedback from other troubled users and considered other solutions: change DNS; block Charter's Web site on the network level; manipulations with browser settings -- for example, Dillo, which does not support Javascript, refused to get redirected.
I have tried two solutions: 1) Add "127.0.0.1 [offending URL]" into /etc/hosts. The browsers will then say that the offending URL does not exist. 2) NoRedirect for Firefox. This one works just for Firefox (of course), but it fixes the problem completely (I get notified that the URL I typed does not exist, not that the offending one does not exist). I combined both and it seems to be the solution.
MAF 0.12.3 out
2009-05-18Lack of an open-source Web archive format (analogous to MHT) nearly drove me to writing my own format which used the same old way -- archiving a bunch of files into one, and hooking it up to Firefox as an extension. MAF, whose version 0.6 contained Windows binaries and did not work with Firefox 3, seemed frozen at that stage. I force-installed the 0.6 on Firefox and it did open MHTs but did not create files. Today I took a look at MAF's page hoping to see no change and -- lo and behold, the new, system-independent version for Firefox 3 is out! The MAF format (which is a just zip file with the page contents) works flawlessly.
GTK 1.2 font issues
2009-05-16In old GTK1 applications (like xmms, geg, dillo) the fonts are too large by default. The gtkrc file in /usr/share/themes/[theme name]/gtk-2.0 has no effect on them because it relates to GTK 2.0. Finally, I found the workaround.
Create the file .gtkrc-1.2-gnome2 with the content:
include "/usr/share/themes/Default/gtk/gtkrc" style "default-text" { fontset ="-bitstream-bitstream vera sans-medium-r-normal-*-*-90-*-*-p-*-iso10646-1″ } class "GtkWidget" style "default-text"
Source: http://ubuntuforums.org/showthread.php?t=107135
Note: on the source page, due to some reason they advise to create another file and include it into .gtkrc-1.2-gnome2. I have not figured out the reason, and putting the content directly into .gtkrc-1.2-gnome2 worked for me.
chmod recursively
2009-02-01So many times I had this problem: set permissions 644 on all files and 755 on all directories recursively. chmod has the -R option, but it will treat files and directores equally. By googling I found this page; indeed, the power of command line!
find . -type f -exec chmod 644 {} \; #on files only
find . -type d -exec chmod 755 {} \; #on directories only
FlightGear init script
2008-07-19FlightGear (www.flightgear.org) has a Windows version of its startup dialog; on Linux, however, one has to put all the initial parameters in the command line. There is a Linux startup dialog program called fgrun (http://www.viciouslime.co.uk/downloads/cat_view/2-debs), but due to some reason it didn't go well on my distro (Ubuntu 8.04). I remembered a small but useful utility called zenity, and with the help of it and some bash scripting man pages wrote a startup script with a GUI.
===BEGIN FILE=== #! /bin/sh # FlightGear start script example name=$(zenity --entry --title="Enter Callsign" --text "Enter your callsign") plane=$(zenity --list --title="Choose Airplane" \ --column="Airplane" \ "787-ANA" \ "c172p" \ "737-300" \ "A-10" \ "Concorde" \ "Blackbird-A" \ "T38" \ "seahawk" \ "ufo" \ ) airport=$(zenity --list --title="Choose Airport" \ --column="Airport" --column="Location" \ "KSFO" "San Francisco, CA, USA" \ "KATL" "Atlanta, GA, USA" \ "25U" "Imnaha, OR, USA" \ "64S" "Prospect, OR, USA" \ "6WA8" "Greenwater, WA, USA" \ "UUEE" "Moscow, Russia (SVO)" \ "UWGG" "Nizhny Novgorod, Russia" \ ) is_multi=$(zenity --question --text "Server login?"; echo $?) case $is_multi in 0) multi="--multiplay=out,10,mpserver02.flightgear.org,5000";; 1) multi="";; esac fgfs --aircraft=$plane --callsign=$name --airport=$airport $multi --timeofday=noon ===END FILE===
*.mht file issues
2008-07-06*.mht Internet Explorer Web archives can be easily opened with Opera (http://www.opera.com). In my experience, not all of them were handled correctly by Opera. Mozilla Archive Format (http://maf.mozdev.org) Firefox extension seems to be frozen at its version for Firefox 1.5 and it claims to be for Windows only. Following advice on Ubuntu Forums, I just edited install.rdf by putting the maximum Firefox version as 3.* and repackaged it. It opens *.mht files perfectly -- those which didn't show well in Opera were good in this one. Unfortunately, the capability of saving pages into MAF or MHT files does not function.
Interactive directory opened
2008-04-05I've been thinking about it for quite a time since frequent content editing in a regular HTML page requires much more than posting here; besides, there is no option of content commenting. Thus, the necessity of getting a blog made me look through some blog scripts and check them out. Surprisingly, there were not too many of them that I would like. The best one that I came across is Bloly blog script — a nice-looking minimalist no-junk blog. Due to some reason it did not allow anonymous comments and its registration script did not deliver the passwords to the two email addresses I tested it on. Well, too bad. I checked out one more that I liked (forgot the name), but its not being open source and the license which prohibited editing the scripts made it unacceptable. [EDIT 2008-04-06: remembered the name: aFlog] I went through some more but due to one or another reason they did not work for me either. After some thinking, I decided to use a phpbb forum for this purpose — I have some experience with it (administered one for a year), and it has even more functionality that a standard blog script.
So I came across this forum script and found it better for here: it does not take as much disk space as does phpbb and it uses fewer mysql tables.
Abandoning ICQ chat protocol
2008-03-20Beginning March 30, 2008, I will stop using the ICQ instant message protocol. This decision was made taking into account the overall poor quality of ICQ service, its user-unfriendly attitude, and the consequent loss of popularity (no one really uses it now anymore, except for Russia and probably some other countries, where it still seems to be popular). Anyone who uses the ICQ protocol via any chat client (ICQ5, LICQ, QIP, or any multi-protocol client using the ICQ protocol) will not be able to contact me after March 30, 2008 via ICQ.
If you want to contact me in an instant-message network after March 30, 2008, I am currently available in four of them.
- Jabber (e.g., Google Talk): my ID is [...]@gmail.com (preferred)
- Mail.ru Agent: my ID is [...]@mail.ru
- MSN: my ID is [...]@gmail.com
- Yahoo: my ID is [...]@yahoo.com
Начиная с 30 марта 2008 г. я перестану использовать чат-протокол ICQ. Это решение было сделано исходя из некачественности данной службы, недружелюбности по отношению к пользователям и, как следствие, потери популярности (вряд ли кто-либо сейчас до сих пор использует ICQ, за исключением России и, возможно, некоторых других стран, где он все еще пользуется популярностью). Все те, кто используют протокол ICQ с каким угодно чат-клиентом (ICQ5, LICQ, QIP, или любой мультипротокольный клиент, использующий ICQ), не смогут связаться со мной после 30 марта 2008 г. через ICQ.
Если Вы хотите связаться со мной через чат после 30 марта 2008 г., я доступен в нижеследующих четырех чат-протоколах:
- Jabber (например, Google Talk): мой логин — [...]@gmail.com (предпочтительный вариант)
- Mail.ru Агент: мой логин — [...]@mail.ru
- MSN: мой логин — [...]@gmail.com
- Yahoo: мой логин — [...]@yahoo.com
Related links:
- http://my.opera.com/mamapapalong/blog/2008/04/25/the-end-of-icq-icq-is-officially-dead
- http://stop-icq.blogspot.com (Russian)
- http://e-novosti.info/forumo/viewtopic.php?t=2665 (Russian)
2009-07-29 update: It's been half a year or so since I stopped using Yahoo and Mail.ru chat services, mainly due to absence of correspondents on those networks or their availability on Jabber or MSN.
Getting rid of .serverauth.???? files
2008-03-19A manual on how to get rid of .serverauth.???? files generated in your home directory. This seems to happen to those who log in from console rather than use (unnecessary) graphic login managers like gdm.
Cleaning up Ubuntu installation
2008-03-07Due to lack of free disk space on small hard drives or just to keep the system free from the stuff that I don't need, I made a small shell script which removes unneeded software which is installed in Ubuntu Linux by default (Ubuntu does not give you the option of selecting desired software during install). This list is made for Ubuntu 6.06. Packages to remove include the following:
- gdm: graphical login manager (console login is faster, and you can start the GUI by doing "startx" or configuring .bash_profile or .xinitrc. Frees about 12 M.
- ubuntu-artwork, tango-icon-theme, ubuntu-sounds, gnome-themes, xcursor-themes: all so-called "eye-candy", desktop wallpapers, fancy mouse cursors, and the like. You might have to do "sudo dpkg-reconfigure xserver-xorg" if your X does not start, or just edit /etc/X11/xorg.conf. After this, you have just one "Custom" theme in the Themes control window. I use "Redmond" for the color scheme in "Theme details" with my customized colors (see below).
- gnome-accessibility-themes, gnopernicus: accessibility features.
- example-content: just deletes the folder /usr/share/example-content with sample text and media files.
- gnome2-user-guide: a huge help package which hardly anyone will use (google is your friend anyway).
- ttf-arabeyes, ttf-arphic-ukai, ttf-arphic-uming, ttf-baekmuk, ttf-bengali-fonts, ttf-devanagari-fonts, ttf-kochi-gothic, ttf-kochi-mincho, ttf-thai-tlwg: Asian and Arabic TTF fonts.
- gaim, gnome-terminal: unnecessary software which is either unused or replaced by better alternatives (Gaim is inferior to Psi or Pidgin, and I use xterm anyway).
You can download the script here.
How to play Shockwave on Linux
2008-02-19Once I had to use a site with Shockwave and it didn't work in my Firefox. As I found out, Shockwave was not Linux-friendly. All right, in this case I would have to tell it that I was not Linux. :) Thanks to this wonderful advice everything worked. I ran the Firefox 1.5 installer for Windows under Wine (Firefox 2.0 didn't work due to some reason), then opened the unfriendly site in it. Firefox suggested downloading the Shockwave plugin. Voila!
My programming exercises
Old Pascal programs
Miscellaneous
- My customized theme for GTK "Redmond" theme for Ubuntu Linux 10.04 (put in /usr/share/themes/Redmond/gtk*).
- WinClassic - my old project which changed Windows XP GUI into Windows NT 4.0 or Windows 98 GUI almost completely